Back
Soundtouch - GUI
What Is Sound?
All sounds are vibrations traveling through the air as sound waves. Sound waves
are caused by the vibrations of objects and radiate outward from their source in
all directions. A vibrating object compresses the surrounding air molecules (squeezing
them closer together) and then rarefies them (pulling them farther apart). Although
the fluctuations in air pressure travel outward from the object, the air molecules
themselves stay in the same average position. As sound travels, it reflects off
objects in its path, creating further disturbances in the surrounding air. When
these changes in air pressure vibrate your eardrum, nerve signals are sent to your
brain and are interpreted as sound.
Fundamentals of a Sound Wave
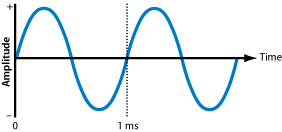
The simplest kind of sound wave is a sine wave. Pure sine waves rarely exist in
the natural world, but they are a useful place to start because all other sounds
can be broken down into combinations of sine waves. A sine wave clearly demonstrates
the three fundamental characteristics of a sound wave: frequency, amplitude, and
phase.
Frequency
Frequency is the rate, or number of times per second, that a sound wave cycles from
positive to negative to positive again. Frequency is measured in cycles per second,
or hertz (Hz). Humans have a range of hearing from 20 Hz (low) to 20,000 Hz (high).
Frequencies beyond this range exist, but they are inaudible to humans.
Amplitude
Amplitude (or intensity) refers to the strength of a sound wave, which the human
ear interprets as volume or loudness. People can detect a very wide range of volumes,
from the sound of a pin dropping in a quiet room to a loud rock concert. Because
the range of human hearing is so large, audio meters use a logarithmic scale (decibels)
to make the units of measurement more manageable.
Phase
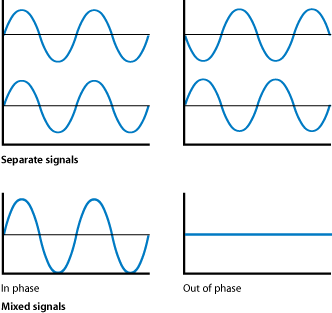
Phase compares the timing between two similar sound waves. If two periodic sound
waves of the same frequency begin at the same time, the two waves are said to be
in phase. Phase is measured in degrees from 0 to 360, where 0 degrees means both
sounds are exactly in sync (in phase) and 180 degrees means both sounds are exactly
opposite (out of phase). When two sounds that are in phase are added together, the
combination makes an even stronger result. When two sounds that are out of phase
are added together, the opposing air pressures cancel each other out, resulting
in little or no sound. This is known as phase cancelation.
Phase cancelation can be a problem when mixing similar audio signals together, or
when original and reflected sound waves interact in a reflective room. For example,
when the left and right channels of a stereo mix are combined to create a mono mix,
the signals may suffer from phase cancelation.
Frequency Spectrum of Sounds
With the exception of pure sine waves, sounds are made up of many different frequency
components vibrating at the same time. The particular characteristics of a sound
are the result of the unique combination of frequencies it contains.
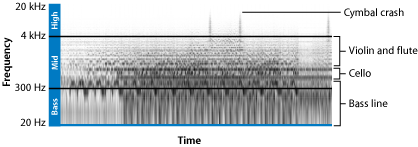
Sounds contain energy in different frequency ranges, or bands. If a sound has a
lot of low-frequency energy, it has a lot of bass. The 250–4000 Hz frequency band,
where humans hear best, is described as midrange. High-frequency energy beyond the
midrange is called treble, and this adds crispness or brilliance to a sound. The
graph below shows how the sounds of different musical instruments fall within particular
frequency bands.
Note: Different manufacturers and mixing engineers define the ranges of these frequency
bands differently, so the numbers described above are approximate.
The human voice produces sounds that are mostly in the 250–4000 Hz range, which
likely explains why people’s ears are also the most sensitive to this range. If
the dialogue in your movie is harder to hear when you add music and sound effects,
try reducing the midrange frequencies of the nondialogue tracks using an equalizer
filter. Reducing the midrange creates a “sonic space” in which the dialogue can
be heard more easily.
Musical sounds typically have a regular frequency, which the human ear hears as
the sound’s pitch. Pitch is expressed using musical notes, such as C, E flat, and
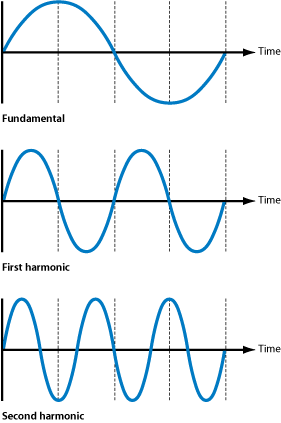
F sharp. The pitch is usually only the lowest, strongest part of the sound wave,
called the fundamental frequency. Every musical sound also has higher, softer parts
called overtones or harmonics, which occur at regular multiples of the fundamental
frequency. The human ear doesn’t hear the harmonics as distinct pitches, but rather
as the tone color (also called the timbre) of the sound, which allows the ear to
distinguish one instrument or voice from another, even when both are playing the
same pitch.
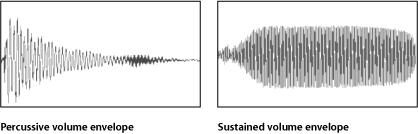
Musical sounds also typically have a volume envelope. Every note played on a musical
instrument has a distinct curve of rising and falling volume over time. Sounds produced
by some instruments, particularly drums and other percussion instruments, start
at a high volume level but quickly decrease to a much lower level and die away to
silence. Sounds produced by other instruments, for example, a violin or a trumpet,
can be sustained at the same volume level and can be raised or lowered in volume
while being sustained. This volume curve is called the sound’s envelope and acts
like a signature to help the ear recognize what instrument is producing the sound.
Measuring Sound Intensity
Human ears are remarkably sensitive to vibrations in the air. The threshold of human
hearing is around 20 microPascals (μP), which is an extremely small amount of atmospheric
pressure. At the other extreme, the loudest sound a person can withstand without
pain or ear damage is about 200,000,000 μP: for example, a loud rock concert or
a nearby jet airplane taking off.
Because the human ear can handle such a large range of intensities, measuring sound
pressure levels on a linear scale is inconvenient. For example, if the range of
human hearing were measured on a ruler, the scale would go from 1 foot (quietest)
to over 3000 miles (loudest)! To make this huge range of numbers easier to work
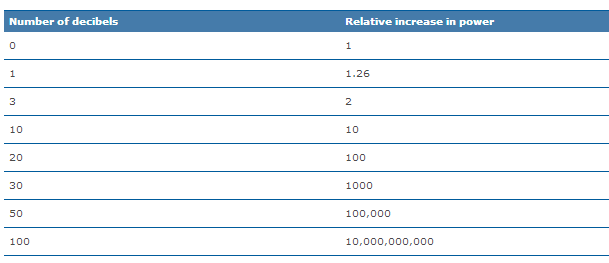
with, a logarithmic unit—the decibel—is used. Logarithms map exponential values
to a linear scale. For example, by taking the base-ten logarithm of 10 (101) and
1,000,000,000 (109), this large range of numbers can be written as 1–9, which is
a much more convenient scale.
Because the ear responds to sound pressure logarithmically, using a logarithmic
scale corresponds to the way humans perceive loudness. Audio meters and sound measurement
equipment are specifically designed to show audio levels in decibels. Small changes
at the bottom of an audio meter may represent large changes in signal level, while
small changes toward the top may represent small changes in signal level. This makes
audio meters very different from linear measuring devices like rulers, thermometers,
and speedometers. Each unit on an audio meter represents an exponential increase
in sound pressure, but a perceived linear increase in loudness.
Important: When you mix audio, you don’t need to worry about the mathematics behind
logarithms and decibels. Just be aware that to hear incremental increases in sound
volume, exponentially more sound pressure is required.
What Is a Decibel?
The decibel measures sound pressure or electrical pressure (voltage) levels. It
is a logarithmic unit that describes a ratio of two intensities, such as two different
sound pressures, two different voltages, and so on. A bel (named after Alexander
Graham Bell) is a base-ten logarithm of the ratio between two signals. This means
that for every additional bel on the scale, the signal represented is ten times
stronger. For example, the sound pressure level of a loud sound can be billions
of times stronger than a quiet sound. Written logarithmically, one billion (1,000,000,000
or 109) is simply 9. Decibels make the numbers much easier to work with.
In practice, a bel is a bit too large to use for measuring sound, so a one-tenth
unit called the decibel is used instead. The reason for using decibels instead of
bels is no different from the reason for measuring shoe size in, say, centimeters
instead of meters; it is a more practical unit.
Decibel Units
Audio meters are labeled with decibels. Several reference levels have been used
in audio meters over the years, starting with the invention of the telephone and
evolving to present day systems. Some of these units are only applicable to older
equipment. Today, most professional equipment uses dBu, and most consumer equipment
uses dBV. Digital meters use dBFS.
- dBm: The m stands for milliwatt (mW), which is a unit for measuring electrical power.
(Power is different from electrical voltage and current, though it is related to
both.) This was the standard used in the early days of telephone technology and
remained the professional audio standard for years.
- dBu: This reference level measures voltage instead of power, using a reference level
of 0.775 volts. dBu has mostly replaced dBm on professional audio equipment. The
u stands for unloaded, because the electrical load in an audio circuit is no longer
as relevant as it was in the early days of audio equipment.
- dBV: This also uses a reference voltage like dBu, but in this case the reference
level is 1 volt, which is more convenient than 0.775 volts in dBu. dBV is often
used on consumer and semiprofessional devices.
- dBFS: This scale is very different from the others because it is used for measuring
digital audio levels. FS stands for full-scale, which is used because, unlike analog
audio signals that have an optimum signal voltage, the entire range of digital values
is equally acceptable when using digital audio. 0 dBFS is the highest-possible digital
audio signal you can record without distortion. Unlike analog audio scales like
dBV and dBu, there is no headroom past 0 dBFS.
Signal-to-Noise Ratio
Every electrical system produces a certain amount of low-level electrical activity
called noise. The noise floor is the level of noise inherent in a system. It is
nearly impossible to eliminate all the noise in an electrical system, but you don’t
have to worry about the noise if you record your signals significantly higher than
the noise floor. If you record audio too low, you raise the volume to hear it, which
also raises the volume of the noise floor, causing a noticeable hiss.
The more a signal is amplified, the louder the noise becomes. Therefore, it is important
to record most audio around the nominal (ideal) level of the device, which is labeled
0 dB on an analog audio meter.
The signal-to-noise ratio, typically measured in dB, is the difference between the
nominal recording level and the noise floor of the device. For example, the signal-to-noise
ratio of an analog tape deck may be 60 dB, which means the inherent noise in the
system is 60 dB lower than the ideal recording level.
Headroom and Distortion
If an audio signal is too strong, it will overdrive the audio circuit, causing the
shape of the signal to distort. In analog equipment, distortion increases gradually
the more the audio signal overdrives the circuit. For some audio recordings, this
kind of distortion can add a unique “warmth” to the recording that is difficult
to achieve with digital equipment. However, for audio post-production, the goal
is to keep the signal clean and undistorted.
0 dB on an analog meter refers to the ideal recording level, but there is some allowance
for stronger signals before distortion occurs. This safety margin is known as headroom,
meaning that the signal can occasionally go higher than the ideal recording level
without distorting. Having headroom is critical when recording, especially when
the audio level is very dynamic and unpredictable. Even though you can adjust the
recording level while you record, you can’t always anticipate quick, loud sounds.
The extra headroom above 0 dB on the meter is there in case the audio abruptly becomes
loud.
Dynamic Range and Compression
Dynamic range is the difference between the quietest and loudest sound in your mix.
A mix that contains quiet whispers and loud screams has a large dynamic range. A
recording of a constant drone such as an air conditioner or steady freeway traffic
has very little amplitude variation, so it has a small dynamic range.
You can actually see the dynamic range of an audio clip by looking at its waveform.
For example, two waveforms are shown below. The top one is a section from a well-known
piece of classical music. The bottom one is from a piece of electronic music. From
the widely varied shape of the waveform, you can tell that the classical piece has
the greater dynamic range.

Notice that the loud and soft parts of the classical piece vary more frequently,
as compared to the fairly consistent levels of the electronic music. The long, drawn-out
part of the waveform at the left end of the top piece is not silence—it’s actually
a long, low section of the music.
Dynamic sound has drastic volume changes. Sound can be made less dynamic by reducing,
or compressing, the loudest parts of the signal to be closer to the quiet parts.
Compression is a useful technique because it makes the sounds in your mix more equal.
For example, a train pulling into the station, a man talking, and the quiet sounds
of a cricket-filled evening are, in absolute terms, very different volumes. Because
televisions and film theaters must compete with ambient noise in the real world,
it is important that the quiet sounds are not lost.
The goal is to make the quiet sounds (in this case, the crickets) louder so they
can compete with the ambient noise in the listening environment. One approach to
making the crickets louder is to simply raise the level of the entire soundtrack,
but when you increase the level of the quiet sounds, the loud sounds (such as the
train) get too loud and distort. Instead of raising the entire volume of your mix,
you can compress the loud sounds so they are closer to the quiet sounds. Once the
loud sounds are quieter (and the quiet sounds remain the same level), you can raise
the overall level of the mix, bringing up the quiet sounds without distorting the
loud sounds.
When used sparingly, compression can help you bring up the overall level of your
mix to compete with noise in the listening environment. However, if you compress
a signal too far, it sounds very unnatural. For example, reducing the sound of an
airplane jet engine to the sound of a quiet forest at night and then raising the
volume to maximum would cause the noise in the forest to be amplified immensely.
Different media and genres use different levels of compression. Radio and television
commercials use compression to achieve a consistent wall of sound. If the radio
or television becomes too quiet, the audience may change the channel—a risk advertisers
and broadcasters don’t want to take. Films in theaters have a slightly wider dynamic
range because the ambient noise level of the theater is lower, so quiet sounds can
remain quiet.
Stereo Audio
The human ear hears sounds in stereo, and the brain uses the subtle differences
in sounds entering the left and right ears to locate sounds in the environment.
To re-create this sonic experience, stereo recordings require two audio channels
throughout the recording and playback process. The microphones must be properly
positioned to accurately capture a stereo image, and speakers must also be spaced
properly to re-create a stereo image accurately.
If any part of the audio reproduction pathway eliminates one of the audio channels,
the stereo image will most likely be compromised. For example, if your playback
system has a CD player (two audio channels) connected to only one speaker, you will
not hear the intended stereo image.
Important: All stereo recordings require two channels, but two-channel recordings
are not necessarily stereo. For example, if you use a single-capsule microphone
to record the same signal on two tracks, you are not making a stereo recording.
Identifying Two-Channel Mono Recordings
When you are working with two-channel audio, it is important to be able to distinguish
between true stereo recordings and two tracks used to record two independent mono
channels. These are called dual mono recordings.
Examples of dual mono recordings include:
- Two independent microphones used to record two independent sounds, such as two different
actors speaking. These microphones independently follow each actor’s voice and are
never positioned in a stereo left-right configuration. In this case, the intent
is not a stereo recording but two discrete mono channels of synchronized sound.
- Two channels with exactly the same signal. This is no different than a mono recording,
because both channels contain exactly the same information. Production audio is
sometimes recorded this way, with slightly different gain settings on each channel.
This way, if one channel distorts, you have a safety channel recorded at a lower
level.
- Two completely unrelated sounds, such as dialogue on track 1 and a timecode audio
signal on track 2, or music on channel 1 and sound effects on channel 2. Conceptually,
this is not much different than recording two discrete dialogue tracks in the example
above.
The important point to remember is that if you have a two-track recording system,
each track can be used to record anything you want. If you use the two tracks to
record properly positioned left and right microphones, you can make a stereo recording.
Otherwise, you are simply making a two-channel mono recording.
Identifying Stereo Recordings
When you are trying to decide how to work with an audio clip, you need to know whether
a two-channel recording was intended to be stereo or not. Usually, the person recording
production sound will have labeled the tapes or audio files to indicate whether
they were recorded as stereo recordings or dual-channel mono recordings. However,
things don’t always go as planned, and tapes aren’t always labeled as thoroughly
as they should be. As an editor, it’s important to learn how to differentiate between
the two.
Here are some tips for distinguishing stereo from dual mono recordings:
- Stereo recordings must have two independent tracks. If you have a tape with only
one track of audio, or a one-channel audio file, your audio is mono, not stereo.
Note: It is possible that a one-channel audio file is one half of a stereo pair.
These are known as split stereo files, because the left and right channels are contained
in independent files. Usually, these files are labeled accordingly: AudioFile.L
and AudioFile.R are two audio files that make up the left and right channels of
a stereo sound.
- Almost all music, especially commercially available music, is mixed in stereo.
- Listen to a clip using two (stereo) speakers. If each side sounds subtly different,
it is probably stereo. If each side sounds absolutely the same, it may be a mono
recording. If each side is completely unrelated, it is a dual mono recording.
Interleaved Versus Split Stereo Audio Files
Digital audio can send a stereo signal within a single stream by interleaving the
digital samples during transmission and deinterleaving them on playback. The way
the signal is stored is unimportant as long as the samples are properly split to
left and right channels during playback. With analog technology, the signal is not
nearly as flexible.
Split stereo files are two independent audio files that work together, one for the
left channel (AudioFile.L) and one for the right channel (AudioFile.R). This mirrors
the traditional analog method of one track per channel (or in this case, one file
per channel).
Back