The following table gives some training data to be used in the classification of
flower types. Petal length and width are given for two different flowers. Plot this
information on a graph (utilizing the same scale for the petal length and
petal width axes) and then answer the questions below.
------------------------------------
| Petal Length | Petal Width | Class |
|--------------+-------------+-------|
| 4 | 3 | 1 |
|--------------+-------------+-------|
| 4.5 | 4 | 1 |
|--------------+-------------+-------|
| 3 | 4 | 1 |
|--------------+-------------+-------|
| 6 | 1 | 2 |
|--------------+-------------+-------|
| 7 | 1.5 | 2 |
|--------------+-------------+-------|
| 6.5 | 2 | 2 |
------------------------------------
a) Calculate the mean, or prototype, vectors
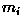 for the two flower types described above. b) Determine the decision
functions
for the two flower types described above. b) Determine the decision
functions
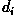 for each class. c) Determine the equation of the boundary (i.e.
for each class. c) Determine the equation of the boundary (i.e.
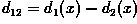 ) and plot the decision surface
on your graph. d) Notice that substitution of a pattern from class
) and plot the decision surface
on your graph. d) Notice that substitution of a pattern from class
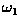 into your answer from the previous section yields a positive valued
into your answer from the previous section yields a positive valued
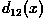 , while a pattern belonging to the
class
, while a pattern belonging to the
class
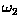 yields a negative value. How would you use this information to determine a new pattern's
class membership?
yields a negative value. How would you use this information to determine a new pattern's
class membership?